Logický myšlenkový řetězec (LogiCoT) je zaměřen na zlepšení schopnosti nulového uvažování velkých jazykových modelů (LLM) začleněním principů ze symbolické logiky.
Metodika LogiCoT zahrnuje dvojí proces:
- za prvé, použití reductio ad absurdum k identifikaci a opravě logických chyb v rámci argumentačního řetězce;
- za druhé, strukturování procesu uvažování, které umožňuje systematické ověřování a revizi každého argumentačního kroku na základě logických principů.
Tento proces je doplněn zavedením mechanismu růstu řetězce, který selektivně reviduje nepravděpodobné kroky uvažování, čímž zvyšuje přesnost uvažování modelu bez zbytečné výpočetní zátěže.
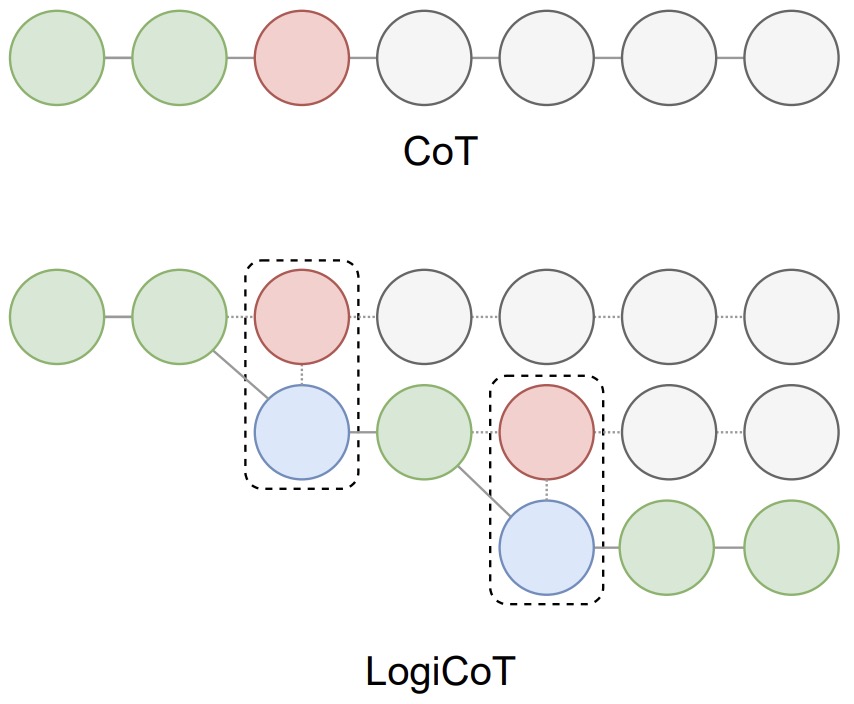
Na obrázku níže je znázorněn přehled podnětů myšlenkového řetězce (CoT) a LogiCoT. V případě CoT činí selhání entailmentu (červeně) zbytek dedukce nedůvěryhodným (šedě), což v důsledku brání celkovému úspěchu dedukce. Naproti tomu LogiCoT je navržen tak, aby myslel-ověřoval-revidoval: přijímá ty, které projdou ověřením (zeleně), a reviduje (modře) ty, které neprojdou, čímž efektivně zlepšuje celkovou schopnost usuzování.
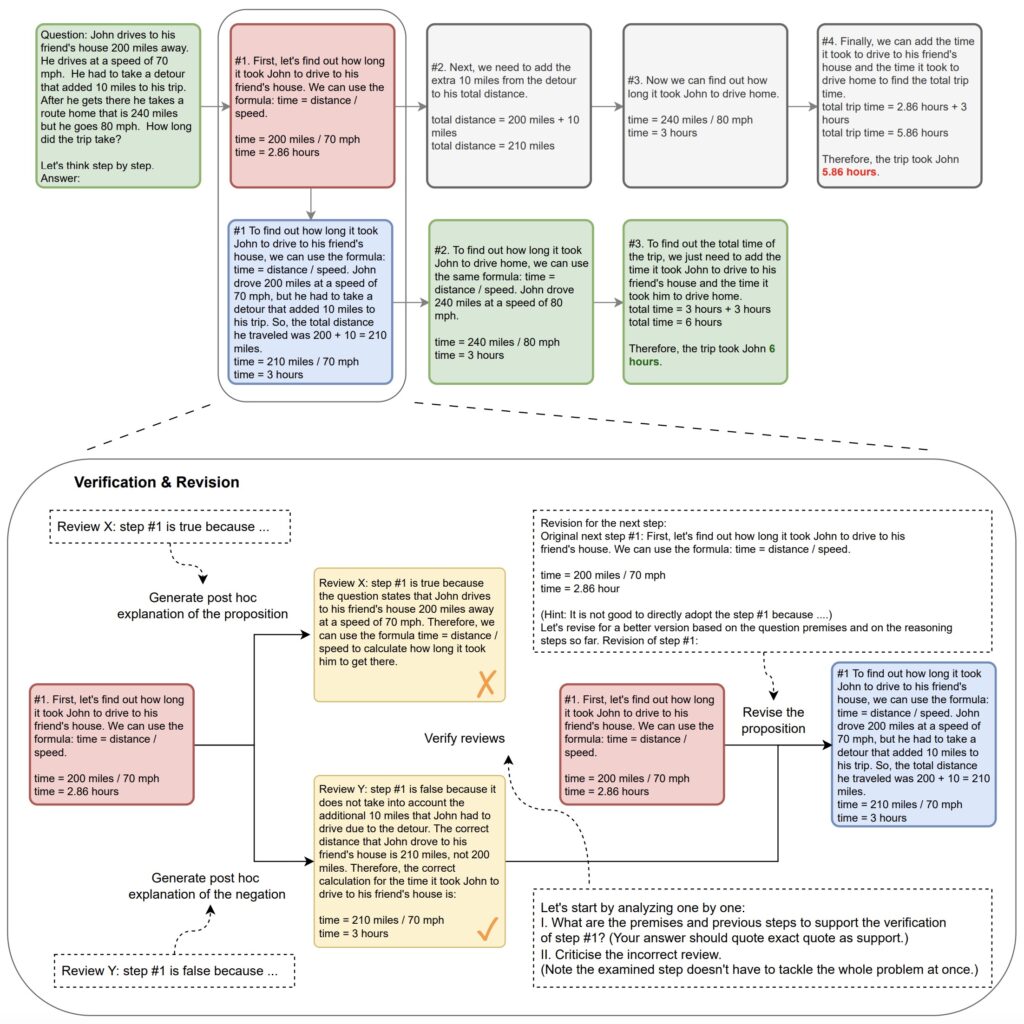
Následující obrázek z článku ukazuje aritmetický příklad při použití verifikace a revize LogiCoT na cestách uvažování CoT.
Každý krok uvažování musí projít verifikační procedurou, která je řízena především dvěma post hoc revizemi generovanými LLM (žlutě) nezávisle.
V tomto příkladu krok č. 1 verifikací neprojde (červeně), protože diskriminátor souhlasí s „revizí Y“, která správně upozorňuje na chybu v tomto kroku. V důsledku toho LLM dále reviduje (modře) původní krok na nový krok č. 1 a na základě revize znovu vygeneruje sledovací cesty. Postup se opakuje, dokud není každý krok ověřen jako platný ( ). Klíčové úryvky výzev použitých k dosažení jednotlivých postupů jsou uvedeny v tečkovaných rámečcích.
Experimentální hodnocení prokazují účinnost systému LogiCoT v různých oblastech, včetně aritmetiky, rozumového uvažování, kauzálních závěrů a úloh sociální interakce.
Zdroje:
Navrhl Zhao a kol. z Hamburské univerzity v článku Enhancing Zero-Shot Chain-of-Thought Reasoning in Large Language Models through Logic.